
Windows Server Summit 2026 | Teil 11: KI-Workloads in Windows Server

KI ist mittlerweile überall, egal, wo man hinschaut. Es haben sich auf dem Markt mehrere große und viele kleine Anbieter etabliert, die jeweils ihre eigenen Stärken und Schwächen haben. Einen großen Knackpunkt haben die meisten Anbieter jedoch - sie sind cloudbasiert.
Windows Server ermöglicht dagegen die Bereitstellung von KI im eigenen Rechenzentrum. Klingt unrealistisch? Bald nicht mehr!
Windows Server als KI-Plattform
Die Grundlage für die KI-Nutzung stellen zwei Hyper-V-Neuerungen dar:
- Die Funktion "GPU-Partitionierung" ermöglicht die Aufteilung von Ressourcen einer physikalischen Grafikkarte auf mehrere virtuelle Maschinen.
- Die Anbindung an NVMe-Speicher erhöht die Speicherleistung drastisch.
Darüber hinaus verfügt Windows Server 2025 über die neue Funktion "Lokale KI-Inferenz". Damit ist es möglich, trainierte KI-Modelle auf eigener Hardware auszuführen. Diese Funktionen bilden zusammen den Grundstein für den lokalen Einsatz von Foundry.
Foundry Local auf Windows Server
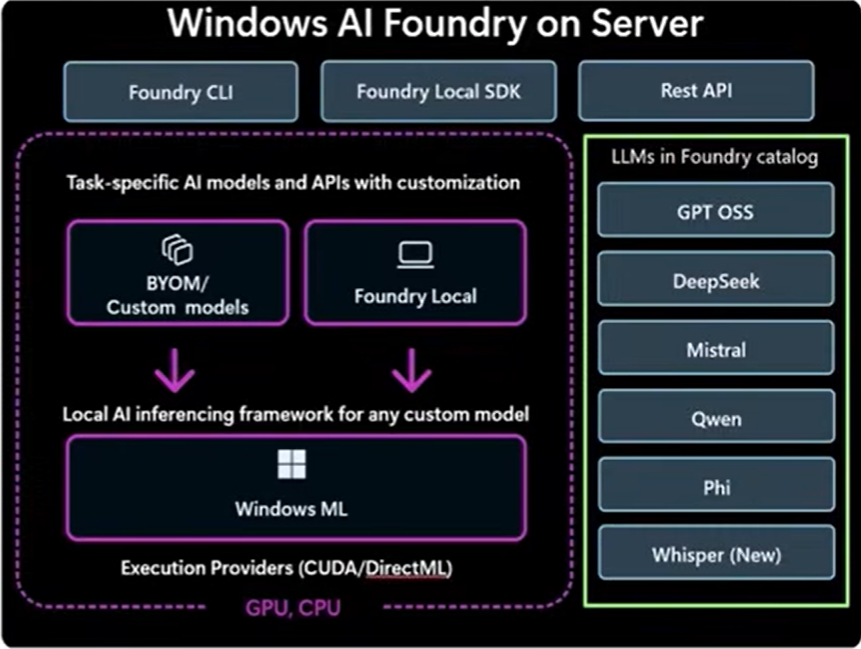
Microsoft Foundry ist eine universelle Plattform zur Erstellung und Wartung von KI-Anwendungen und Agenten. Sie ist bereits in Azure nativ verfügbar.
Foundry Local ist das Pendant für lokale Rechenzentren. Es kann auf Windows Server 2025 und künftigen Windows Server-Versionen ausgeführt werden. Es wird keine spezielle Hardware hierfür benötigt. Es können beliebige Sprachmodelle heruntergeladen und integriert werden.
Die Installation und Verwendung wird in einer kurzen Demo gezeigt (AI workloads on Windows Server - Windows Server Summit, ab Minute 8:38).
Typische Szenarien für KI-Workloads in Windows Server
Die folgende Tabelle zeigt einige Anwendungsszenarien für die lokale Bereitstellung von KI:
| Szenario | Industrie | Details |
|---|---|---|
| Bildverarbeitungsmodelle verwenden, um Qualitätsprobleme in der Verarbeitungskette zu ermitteln | Herstellung | Niedrige Latenz, beschränkte Konnektivität |
| Lokale Modelle verwenden, um KI-Inferenz für die vorbeugende Wartung in vollständig getrennten Systemen durchzuführen | U-Boot | Isolierte Umgebung, KI-Beschleuniger |
| Wissensarbeiter können geistiges Eigentum mittels agentischen Arbeitsabläufen verarbeiten | Gesundheit | Hohe Grenzen für Datenübermittlung, Datenschutz, Nachhaltigkeit, Aufruf von MCP-Lösungen |
| Anwendungsübergreifende Verwendung von generativer KI ermöglichen | FinTech | Hoher Datenschutz, Modellaktualisierungen, Sicherheitsanforderungen |
| KI-zertifizierte Hardware für Dienstanbieter oder Distributoren für SMB herstellen | Hardwarevertrieb | Einfacher Einstieg in lokale KI |
Neuerungen in Foundry Local
Eine neue Funktion ist die Bereitstellung sogenannter Text-Einbettungs-Modelle in Verbindung mit SQL Server 2025. Dies ermöglicht die komplett lokale Bereitstellung einer Plattform für die sogenannte Retrieval-Augmented Generation, was bislang nur unter Einbeziehung von Cloud-Anbietern möglich war (siehe Retrieval-Augmented Generation – Wikipedia).
Weiterhin ist es nun möglich, Lösungen für den Zugriff auf die lokalen KI-Modelle auf Basis des Modellkontextprotokolls (MCP) zu verwenden. Diese ermöglichen eine kontextbasierte Verarbeitung von Daten auf Basis von Benutzereingaben, so wie man es von der Nutzung von Copilot und ChatGPT her kennt.
Bekannte Einschränkungen in Foundry Local
Foundry Local weist einige Einschränkungen auf. So ist es nicht für folgende Szenarien/Umgebungen optimiert:
- Multi-GPU-Grafikkarten
- Verteilte Inferenz
- Failover-Clustering
- Eingeschränkte Parallelität und batchbasierte Inferenz, nur sequenziell
- Nicht für sehr große Unternehmensumgebungen vorgesehen
Andere Optionen
Microsoft nennt noch einige Open-Source-basierte Alternativen zu Foundry Local:
- vLLM
- SGLang
- Ollama
Hat Dir der Beitrag gefallen? Lass es andere wissen!


One thought on “Windows Server Summit 2026 | Teil 11: KI-Workloads in Windows Server”